
Using AI To Fuel Lab-in-the-Loop Approaches in Precision Medicine

You've seen it countless times in the news: "Promising cancer treatment cures mice!" Yet years later, no treatment emerges for humans. This frustrating pattern highlights one of medicine's most persistent challenges – the translational gap.
The problem is fundamental: if you look at the fundamental building blocks, you can see the RNA transcription is different in mice cells and in human cells. Anyone that has been doing pre-clinical experiments knows mouse models aren't predictive of efficacy, but we don’t really know how unrepresentative they are of human tumors.
This isn't just an academic problem—it's costing lives and billions in wasted research dollars.
Thankfully, there are others challenging the status quo. The authors from Novartis found a better way as described in their recent paper, "because of their propagation and differences in growing conditions, they have altered over time, and it is not known how well they represent the biology of the tumors from which they were derived" (p.1).
Enter MOBER: A Deep Learning Bridge
This is where Dimitrieva and colleagues' advanced approach comes in. They've developed MOBER (Multi-Origin Batch Effect Remover), a sophisticated deep learning method that can:
Simultaneously analyze data from cancer cell lines, patient-derived xenografts (PDXs), and actual clinical tumors
Remove confounding variables that typically make comparisons difficult
Identify which lab models most closely resemble real human tumors
Their approach analyzed an impressive dataset:
932 cancer cell lines
434 patient-derived xenografts
11,159 clinical tumors
The results? MOBER successfully identified which preclinical models have the "greatest transcriptional fidelity to clinical tumors" (p.1) and which ones are "transcriptionally unrepresentative" of real cancers.
Real-World Impact: Better Model Selection
Let's get practical. If you're a researcher or pharma company, how does this help you?
You can now select models that actually represent the biology they're studying, potentially saving years of research and millions in funding.
One aspect I found very intriguing: the study found striking differences in how well various cancer models reflect real tumors.
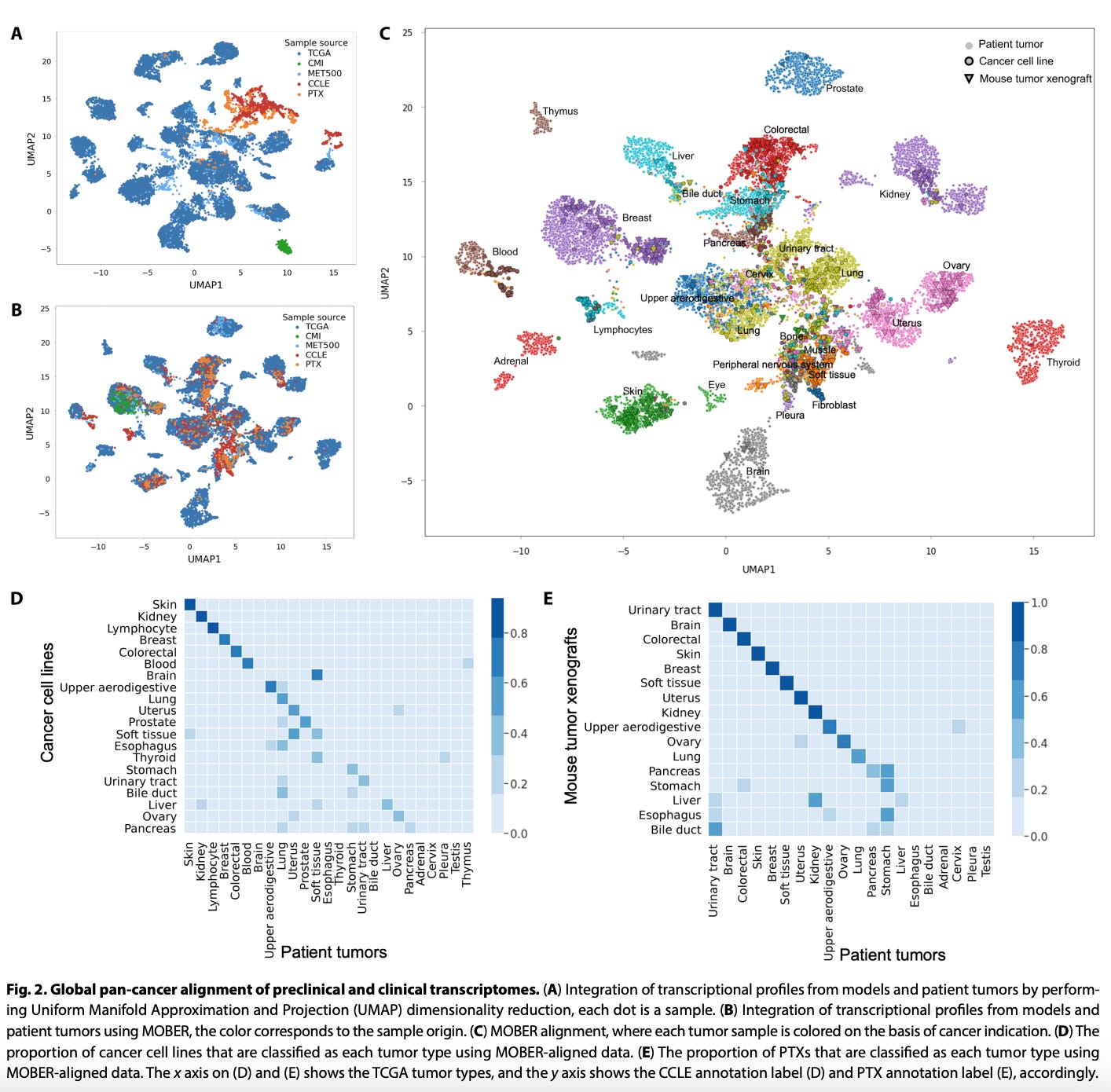
Figure 2: The image shows how MOBER aligns different data sources (A: before alignment showing clear separation by source; B: after alignment showing integration by biological similarities rather than source). Panel C shows alignment by cancer type, while panels D and E show how well cell lines and xenografts align with their purported tumor types.
"Certain cancer types, such as the ones in skin, breast, colorectal, kidney, and uterus, exhibit greater transcriptional similarity between models and patients, while models of cancers of the bile duct, liver, and esophagus have transcriptional profiles that are unlike their patient tumors" (p.6).
This nuanced insight is critical to ensure we are setting up the right preclinical experiments before we give these therapeutics to humans.
Beyond Selection: Transforming Models
But MOBER goes further than just identifying good models. It can actually transform expression profiles from preclinical models to better resemble clinical tumors.
In one compelling example, the team demonstrated how potential biomarkers identified in cell lines using MOBER transformation showed significantly improved clinical translation when applied to patient data:
"Applying these ML models on TCGA patient tumors, we achieve more significant survival stratification of TCGA patient tumors for which we predict very high metastatic potential (top 25%) versus low metastatic potential (bottom 25%) (P = 6.2× 10^-29)" (p.6).

Figure 4: These panels show how MOBER-transformed data improves clinical translation. Panels B and C show survival stratification and clinical stage correlation using untransformed data, while panels D and E show the significantly improved results after MOBER transformation.
That's a dramatic improvement in predictive power that could transform how we develop biomarkers.
Solving the Translation Problem
What makes MOBER superior to previous methods? Three key advantages:
It can integrate multiple datasets simultaneously
It enables transformation of one dataset into another
It makes no assumptions about dataset composition
The team demonstrated that MOBER outperforms traditional batch correction methods like ComBat, Harmony, and Batch Mean Centering (p.3).
But perhaps most importantly, MOBER is interpretable by design—researchers can actually understand what biological differences cause the gap between models and patients.
Where Do We Go From Here?
While MOBER represents a significant advance, the future holds even greater potential when researchers can access thousands of pre-clinical models that are harmonized with large de-identified multimodal patient datasets like those from Tempus.
Imagine combining:
Transcriptomic data (what MOBER currently uses)
Genomic information
Proteomics
De-id Patient outcomes
Treatment responses
The authors acknowledge this potential: "Future version of MOBER that integrates genetic and epigenetic features of models and patient tumors could potentially enable even more detailed analysis between models and patients" (p.6).
We need better model systems and more of them if we want to increase our probability of success in drug development.
Practical Access to These Advances
For those wanting to dig further into these insights, the researchers have made their work accessible:
Open-source code: https://github.com/Novartis/MOBER
Interactive web app: https://mober.pythonanywhere.com
This allows researchers to "explore the MOBER aligned expression profiles coming from cancer models and clinical tumors" and "enables the identification of preclinical models that best represent the transcriptional features of a tumor type" (p.6).
The Bottom Line
As someone working at the intersection of precision medicine and AI, I see MOBER as an essential step toward solving one of our field's most persistent translational challenges.
By bridging the gap between lab and clinic, we can:
Select better preclinical models
Transform imperfect models to better reflect clinical reality
Perform more relevant experiments to de-risk our future clinical trials
What do you think? Are you seeing other AI applications bridging this translational gap in your work? I'd love to hear your experiences in the comments. If you found this helpful, subscribe and join the community focused on building at the intersection of precision medicine x AI.